
티스토리 뷰
위 포스트는 정보문화사에서 출판한 책 '파이썬 딥러닝 파이토치'를 바탕으로 작성되었습니다.
MLP
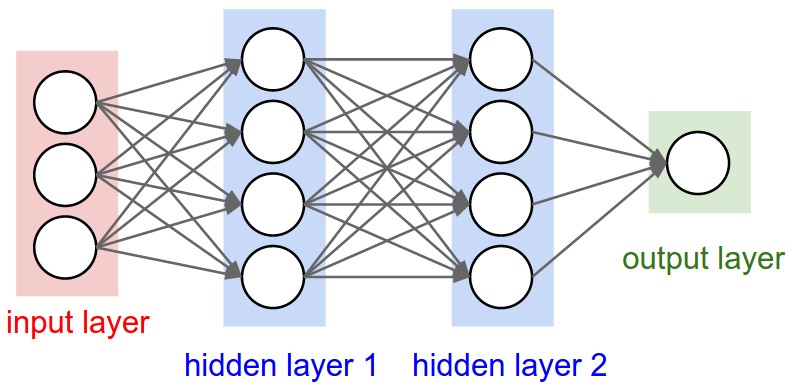
MLP는 여러 개의 퍼셉트론 조합과 이것들의 재조합으로 복잡한 비선형적인 모형을 만들어내는 것을 말한다. MLP의 Hidden Layer를 쌓으면 Layer가 깊어지기 때문에 MLP는 딥러닝의 기본적인 모델이 된다. 이 신경망은 Input에서 Weight와 Hidden을 거쳐 Output을 내보내는데, 이 과정을 'Feed Forward'라 한다.
Back Porapagation
Feed Forward를 이용해 계산하는 output은 우리가 얻고자 하는 예측 값이다. 이 예측값과 실제값의 차이(ERROR)를 계산하고, 이를 바탕으로 신경망의 Weight를 업데이트한다. 이 과정이 바로 'Back Propagation'이다.
Feed Forward와 Back Propagation을 반복하면서 Weight를 업데이트하며 점차 Error 값이 줄어드는 방향으로 학습이 이뤄진다. 여기서 Feed Forward와 Back Propagation 과정을 반복하는 횟수를 'Epoch'라 한다.
신경망 학습순서( Input -> Hidden -> Output -> Error -> )에서 Input ~ Output 은 Feed Forward(데이터에서 예측값을 계산하는 과정), Output에서 Error를 계산해 Weight를 업데이트하는 과정은 Back Propagation 과정이라 할 수 있다.
Gradient Descent Method
Gradient Descent Method는 기울기 경사하강법이라고도 불린다. 경사하강법에 대한 설명은 나의 네** 블로그에 설명한 적이 있다. 이 사이트를 참고하도록!
신경망 학습은 이처럼 Feed Forward와 Back Porpagation을 번갈아가며 진행되고 학습에 따라 점차 학습 데이터에 대한 MSE가 줄어든다. 이때 비효율적인 학습과정을 거치지 않기 위해 데이터를 쪼개서 Feed Forward 하게된다. 전체 데이터가 1,000개라 하면 100개씩 쪼개 Feed Forward와 Back Propagation을 10번 반복한다. 이 하나의 과정(Feed Forward ~ Back Propagation)을 'Epoch'이라 하고, 쪼갠 100개의 데이터를 'Mini-Batch'라 하며 100의 크기를 'Batch Size'라 한다. 이렇게 데이터를 쪼개서 Gradient Descent Method 하는 방법을 Stochastic Gradient Descent(SGD)라 부르며 이를 Optimizer라 한다.
파이토치를 활용한 MNIST MLP 설계하기
이전에 MINIST 데이터셋으로 다층퍼셉트론을 구현한 적이 있다(링크 참고). 그 당시에는 딥러닝 프레임워크도 없고 미니배치도 없는 순전파 과정을 구현했었는데, 이번에는 파이토치를 활용하여 미니배치를 적용한 딥러닝 모델을 구현해보겠다.
MLP 모델 설계순서
1. 모듈 임포트
2. 딥러닝 모델 설계시 활용하는 장비 확인
3. MNIST 데이터 다운로드 (train set, test set 분리하기)
4. 데이터 확인하기
5. MLP 모델 설계
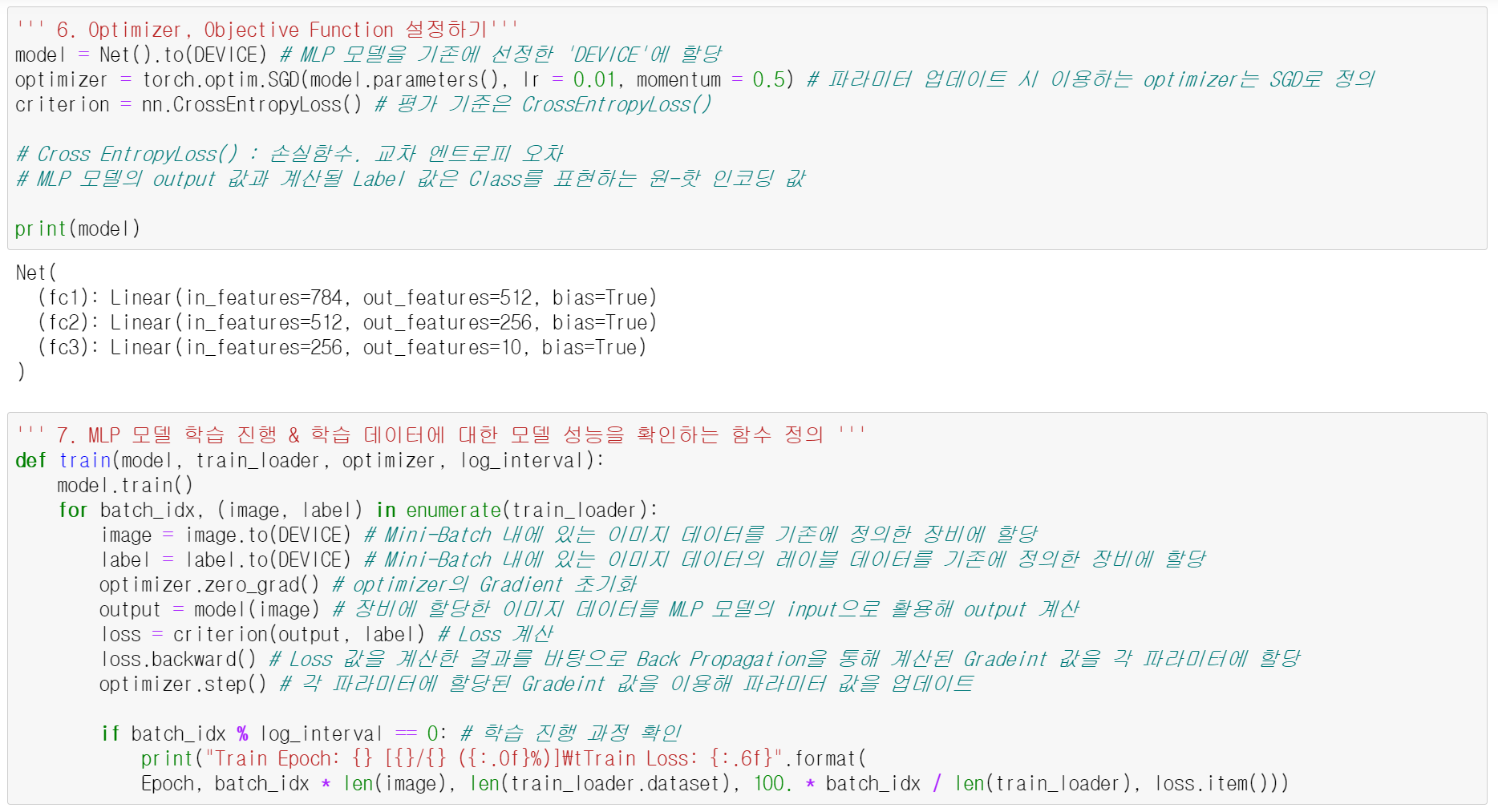
6. Optimizer, Objective Function 설정
7. MLP 모델 학습을 진행하면서 학습 데이터에 대한 모델 성능 확인하는 함수 정의
8. 학습되는 과정 속에서 검증 데이터에 대한 모델의 성능을 확인하는 함수 정의
9. test set Accuracy 확인하기
각 과정에 해당하는 코드는 아래와 같다. 주석을 자세하게 달아봤으니까 참고하면서 읽으면 좋을 것 같다.

✅ 정리하자면
한 번의 iteration = 1개의 mini batch를 이용해 학습하는 것
한 번의 Epoch = 여러 번의 iterations
Epoch = 전체 데이터 학습 횟수

✅ 참고로 MNIST 데이터 셋에서 train_dataset은 60,000개, test_dataset은 10,000개이다.
또한, train-loader에는 1875개의 배치(라고 표현하는 게 맞을지 모르겠지만 아무튼)가 있고 하나의 배치에는 32개의 이미지 데이터가 들어있다(60,000/32 해준 값이라 생각하면 된다). test_loader에는 313개의 배치가 있고 마찬가지로 하나의 배치에 32개의 이미지 데이터가 들어있다(10,000/32). 여기서 기억해야 하는 것은! train-loader.dataset의 길이는 60,000, test-loader.dataset의 길이는 10,000개 라는 것이다(나중에 7번이랑 9번 단계의 출력 과정에서 쓰인다).



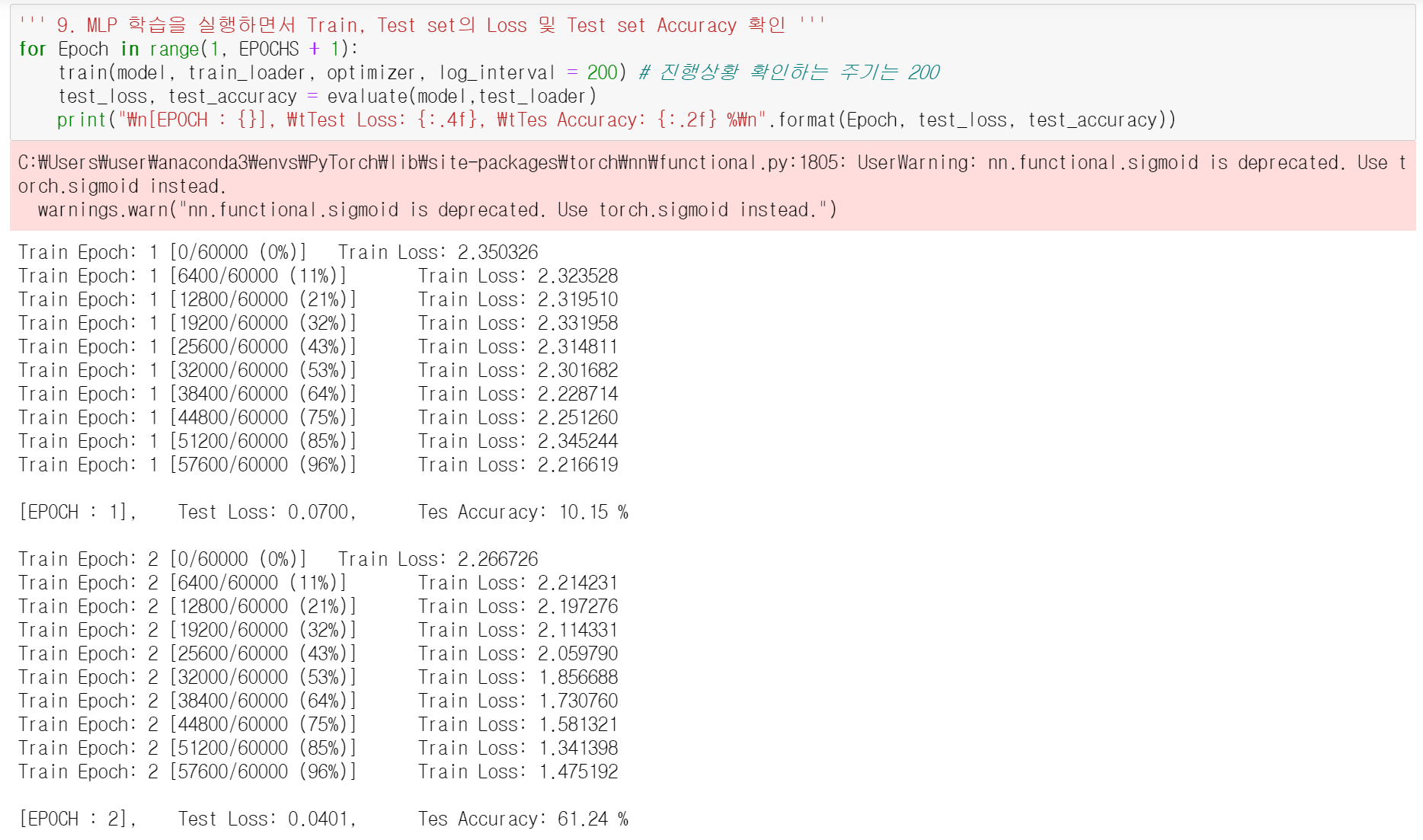
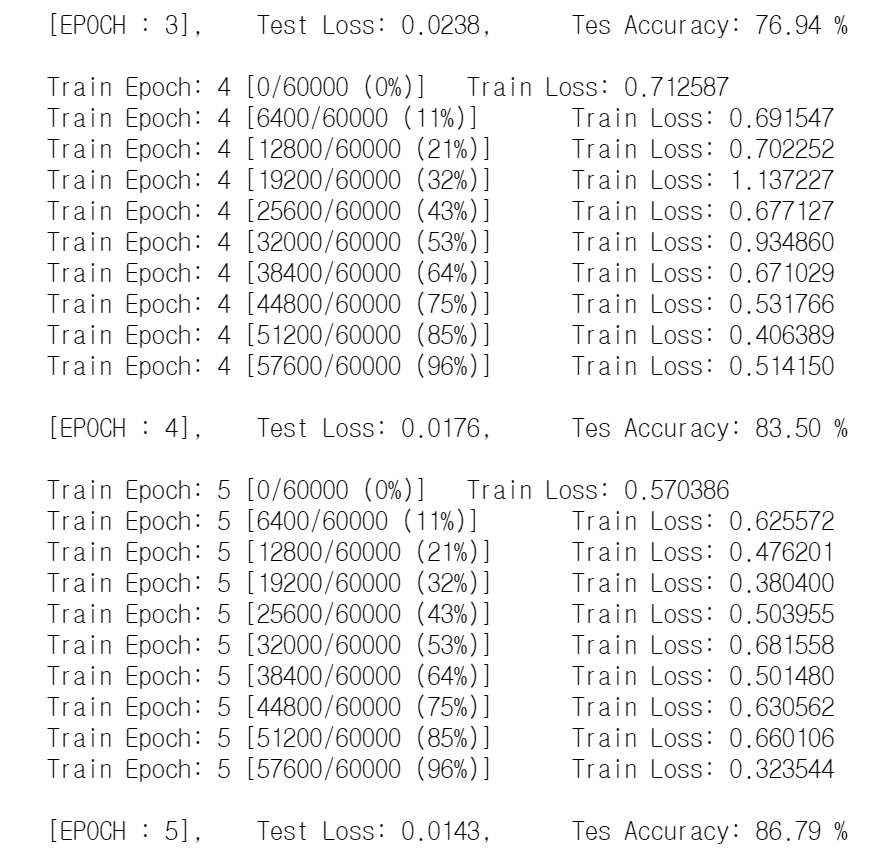

10번의 EPOCH을 거쳐서 최종적으로 Test Accuracy가 90%인 모델이 만들어졌다.
✅ 코드를 실습하면서 가졌던 의문이 있었는데,,
배치 사이즈를 32로 설정하면 총 1875번의 iterations이 반복되야 하는데, 출력하니까 왜 10개의 iterations 밖에 출력되지 않았는가? 였다. 그 이유는 9번 단계에서 log_interval을 200으로 설정했기 때문에, 0,200,400,,,번째의 배치에서만 학습 과정을 출력하는 거였다. 총 1875개의 배치가 있으니 1875/200, 대략 10개의 iteration이 출력되는 게 맞다. 이것 때문에 약 1시간동안 멘붕이었는데 나름 잘 해결한 것 같아서 뿌듯하다.
신경망 모형의 단점
과적합
아직까지 과적합을 완벽하게 해결하는 방안이 없다. 실험 설계를 통해서 적절히 데이터를 나누고 과적합 정도를 파악하여 적절한 모델과 변수를 선택해야 하는 것이다. 신경망의 목적은 결국 학습 데이터 내에서 loss를 최소화하는 것이기 때문에 좀 더 좋은 Decision Boundry를 만드려고 노력하지 않는다.
Gradient Vanishing Problem
기울기가 사라지는 현상을 말한다. Layer가 깊어질수록 Weight의 Gradient는 큰 변화가 없어지고 Weight의 변화도 거의 일어나지 않는다는 것이다. 이론적으로는 Layer가 깊어질수록 신경망은 복잡한 모델을 만들 수 있지만, Back Propagation 과정에서 활성화 함수를 미분한 값을 곱해주는 특성상 실제로는 학습이 잘 이뤄지지 않는다는 단점이 있다. 그래서 Gradient가 감소하지 않도록 여러 Activation 함수가 등장했다.
'딥러닝' 카테고리의 다른 글
| [Deep Learning] Initialization, Optimizer (0) | 2021.07.16 |
|---|---|
| [Deep Learning] Dropout, Activation Function, Batch Normalization (0) | 2021.07.16 |
| [AI Background] 과적합 (0) | 2021.07.11 |
| [AI Background] 머신러닝의 정의와 종류 (0) | 2021.07.10 |
| [AI Background] 인공지능의 사례 (0) | 2021.07.10 |