
티스토리 뷰
위 포스트는 정보문화사에서 출판한 책 <파이썬 딥러닝 파이토치>의 내용을 바탕으로 작성되었습니다.
Autograd
Autograd는 신경망 학습을 지원하는 PyTorch의 자동 미분 엔진이다.
파이토치를 활용 시 Back Propagation을 이용하여 파라미터를 업데이트하는 과정은 Autograd 방식으로 쉽게 구현할 수 있다. 이를 간단한 딥러닝 모델을 설계해보면서 구체적으로 설명해 보겠다.
우선, 전체 코드는 아래와 같다.

위의 전체 코드를 3개의 과정으로 분할하여 차근차근 살펴보자.

(1) cuda.is_available() 메서드 : 현재 파이썬이 실행되고 있는 환경에서 GPU를 계산할 수 있는지를 파악한다.
(2) BATCH_SIZE : 딥러닝 모델에서 파라미터를 업데이트할 때 계산되는 데이터의 개수이다. Input으로 이용되는 데이터 개수를 의미하기도 한다. BATCH_SIZE 수만큼 데이터를 이용해 output을 계산하고, BATCH_SIZE 수만큼 출력된 결괏값에 대한 오찻값을 계산한다. 그리고 BATCH_SIZE 수만큼 계산된 오찻값을 평균해 Back Propagation을 적용하고 이를 바탕으로 파라미터를 업데이트한다.
(3) INPUT_SIZE : 딥러닝 모델에서 Input의 크기이자 입력층의 노드 수를 의미한다. 여기서는 INPUT_SIZE = 1,000 즉, 입력 데이터의 크기가 1,000이라는 것을 의미하며, BATCH_SIZE가 64이므로 크기가 1,000인 벡터를 64개 만들겠다는 의미이다. 이를 모양으로 나타내면 (64,1000)이 된다.
(4) HIDDEN_SIZE : 딥러닝 모델에서 Input을 다수의 파라미터를 이용해 계산한 결과에 한 번 더 계산되는 파라미터 수를 의미한다. 즉, 입력층에서 은닉층으로 전달됐을 때, 은닉층의 노드 수를 의미하는 것이다. 여기서는 (64,1000) 크기의 Input이 (1000,10) 크기의 행렬과 행렬 곱을 계산하기 위해 HIDDEN_SIZE로 1000을 설정하였다.
(5) OUTPUT_SIZE : 딥러닝 모델에서 최종으로 출력되는 값의 벡터의 크기를 의미한다. 보통 최종으로 비교하고자 하는 레이블의 크기와 동일하게 설정한다.

이제 torch.randn 메서드를 이용해 데이터와 파라미터를 설정한다. randn은 평균이 0, 표준편차가 1인 정규분포에서 샘플링한 값으로, 데이터를 만든다는 것을 의미하며 데이터의 모양을 설정할 수 있다.
x
- (64,1000) 모양의 input 데이터
- 생성된 데이터는 미리 설정한 DEVICE를 이용해 계산
- 데이터의 형태는 float
- gradient 계산 X (requires_grad = False)
y
- (64,10) 모양의 output 데이터
- 생성된 데이터는 미리 설정한 DEVICE를 이용해 계산
- 데이터의 형태는 float
- gradient 계산 X (requires_grad = False)
w1
- 업데이트 할 파라미터
- (1000,100) 크기의 데이터
- Input 데이터와 행렬 곱하여 크기가 100인 데이터 생성
- gradient 계산 O (requires_grad = True)
w2
- 업데이트 할 파라미터
- (100,10) 크기의 데이터
- w1과 행렬 곱하여 Output을 계산해야 함
- gradient 계산 O (requires_grad = True)

(1) 파라미터를 업데이트 할 때 Gradient를 계산한 결괏값에 learning_rate를 곱한 값을 이용해 업데이트해줘야 한다(lr을 어떻게 설정하느냐에 따라 Gradient 값에 따른 학습 정도가 달라질 수 있기 때문에 lr은 중요한 하이퍼 파라미터이다).
(2) 위 코드에서는 총 500번의 파라미터 업데이트가 이뤄진다.
(3) 딥러닝 모델의 Input인 x와 Parameter w1 간의 행렬 곱을 이용해 나온 결괏값을 계산한다. 이후 torch 모듈 내 clamp 메서드를 이용하여 비선형 함수를 적용한다(여기서 clamp(min = 0)는 ReLU()와 같은 역할을 한다). clamp를 이용해 계산된 결과와 w2를 이용해 행렬 곱을 한 번 더 계산한다.
* clamp 함수
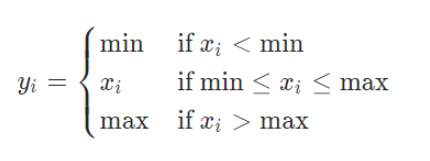
(4) 예측값(y_pred)과 실제 레이블(y) 값을 비교해 오차를 계산하고(loss), Torch Module 내 pow 함수를 이용해 제곱을 취한다. 이후 sum()을 이용해 제곱 차의 합을 계산한다.
(5) 업데이트 반복 횟수가 100,200,300,400,500번 될 때, 진행 중인 반복문 횟수와 Loss 값을 출력하여 코드가 실행되는 과정을 모니터링할 수 있다.
(6) 계산된 Loss 값에 대해 backward() 메서드를 이용하여 각 파라미터 값에 대해 Gradient를 계산하고, Back Propagation을 진행한다. 이때 Autograd가 각 파라미터의. grad 속성에 모델의 각 매개변수에 대한 Gradent를 계산하고 저장한다.
(7) Gradient를 계산한 결과를 이용하여 파라미터 값을 업데이트한다. 이때 해당 시점의 Gradient 값을 고정한 후 업데이트를 진행한다. (코드가 실행되는 시점에서 Gradient 값을 고정한다는 의미)
(8) w1.grad(w1의 Gradient)에 learning_rate 값을 곱하고 난 후, 이 결괏값을 기존의 w1에서 빼준다. 음수를 이용하는 이유는 Loss 값이 최소로 계산될 수 있는 파라미터 값을 찾기 위해 Gradient 값에 대한 반대 방향으로 계산해야 하기 때문이다.
(9) w2에도 w1과 같은 (8) 과정을 적용한다.
(10) 각 파라미터의 업데이트가 끝나면, 파라미터 값의 Gradient를 초기화하고 다음 반복문을 진행할 수 있도록 grad.zero_() 메서드를 적용하여 Gradient 값을 0으로 설정한다.

500번의 업데이트 과정을 거치면서 Loss 값이 줄어드는 것을 확인할 수 있다. Loss 값이 줄어든다는 것은 Input이 w1, w2를 통해 계산된 결괏값과 y 값이 점점 비슷해진다는 것을 의미한다.
지금까지 살펴본 내용이 파이토치의 Autograd 방식으로 구현한 Back Propagation을 이용한 파라미터 업데이트 과정이다.
위 포스트가 단 한 분께라도 도움되었길 바라며, 오늘은 여기까지 쓰겠다!
'딥러닝' 카테고리의 다른 글
| [Deep Learning] Dropout, Activation Function, Batch Normalization (0) | 2021.07.16 |
|---|---|
| [AI Background] 인공 신경망 & MNIST 실습 (0) | 2021.07.13 |
| [AI Background] 과적합 (0) | 2021.07.11 |
| [AI Background] 머신러닝의 정의와 종류 (0) | 2021.07.10 |
| [AI Background] 인공지능의 사례 (0) | 2021.07.10 |