
티스토리 뷰
딥러닝 공부를 하면서 정말 헷갈렸던 것들을 다시 공부해서 정리해보겠다.
잘못된 정보가 있으면 댓글로 지적 부탁드립니다 ^_^
딥러닝 모델에서 feature, 가중치 노드 수가 의미하는 것?
MLP에서 한 레이어에서 다음 레이어로 넘어갈 때 각 노드는 이전 노드의 XW + B(W : 가중치, B : 편향)의 값을 전달받다. 이때 X 는 사용할 데이터의 feature 값이되고 W와 B는 모델이 스스로 학습할 가중치/편향이 된다. 또한 특정 에폭에서 모델을 저장하는 것은 그때 만들어진 가중치와 편향을 저장하는 것이다. 따라서 각 레이어에 들어있는 노드 수는 feature의 개수와 같으며 신경망의 학습은 데이터를 잘 이해/분류할 수 있도록 feature을 추출해내는 weight를 학습시키는 것이라 할 수 있다.
※ 편향의 존재이유?
쉽게말해서 편향은 뉴런(노드)가 얼마나 쉽게 활성화되느냐를 조정하는 매개변수이다.
퍼셉트론의 수식은 다음과 같다.
b + w1x1 + w2x2 < 0 --> 0
b + w1x1 + w2x2 >= 0 --> 1
여기서 이 b 값이 바로 편향이다. 머신러닝 분야에서는 모델이 과적합(train 데이터에서의 모델 성능은 좋으나 test 데이터에서는 제대로 성능을 발휘하지 못하는 것)을 막는 것이 중요한데, 이를 막기 위해 편향이 적용된다.
편향은 학습 데이터가 가중치와 계산되어 넘어야 하는 임계값으로, 이 값이 높을수록 분류되는 기준이 엄격해진다.
그래서 편향이 높을 수록 모델이 간단해지고, 과소적합이 발생할 위험이 높아진다.
반대로 편향이 낮을수록 임계값이 낮아 데이터의 허용범위가 넓어지고, 그만큼 학습 데이터에 잘 들어마즌 모델이 만들어지게 된다(오버피팅)
MLP
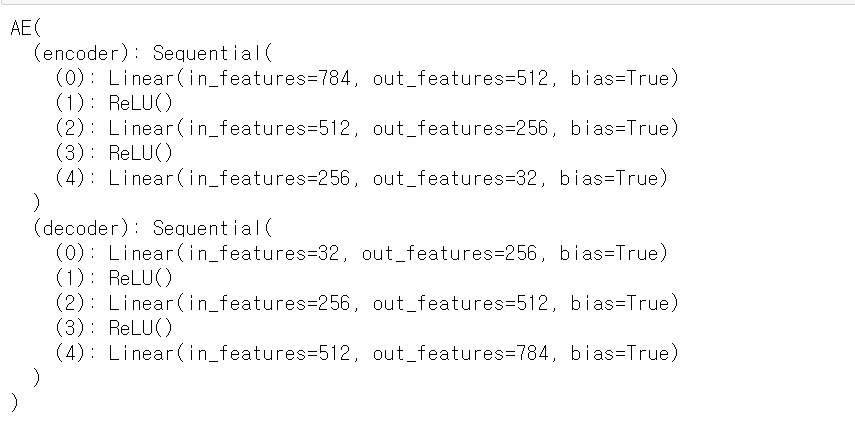

예를 들어 AutoEncoder 모델의 내부를 보자. 모델에 input은 28*28 픽셀의 흑백 이미지이다. 총 784개의 픽셀을 한 줄로 늘어뜨려 input 데이터로 만든다. 따라서 인코더의 첫 번째 레이어는 784개의 노드가 들어가야 한다. 그리고 내부를 살펴보면 두 번재 레이어에는 512개의 노드가, 세 번째 레이어에는 256개의 노드가 들어있음을 알 수 있다. (output shape 에서 보이는 -1은 한 배치 묶음에 들어있는 이미지 개수를 의미)

CNN

CNN 모델구조를 알기위해선 합성곱 계층(conv)에 대한 이해가 필요하다. 그래서 우선 합성곱 계층에 대해서 간단하게 정리해보고 실제 모델의 구조를 살펴보자.(쓰다보니 간단해지진 않았다..)
합성곱 계층
합성곱 계층 설명
데이터의 형상을 무시하여 데이터의 정보를 제대로 담을 수 없는 완전연결 계층과 달리 CNN애는 형상을 유지할 수 있는 합성곱 계층이 존재한다. 합성곱 계층은 3차원 이미지를 입력받으면, 다음 계층에도 마찬가지로 3차원 데이터를 전달할 수 있다.
CNN에서 자주 등장하는 용어가 특징 맵(feature map)인데, 이는 합성곱 계층의 입출력 데이터를 말한다. 합성곱 계층의 입력 데이터는 입력 특징 맵(input feature map), 출력 데이터는 출력 특징 맵(output feature map)이라고 한다.
합성곱 연산
1. 2차원 데이터의 합성곱 연산
2차원 형상을 다루는 합성곱 연산(필터연산)의 예시는 다음과 같다.
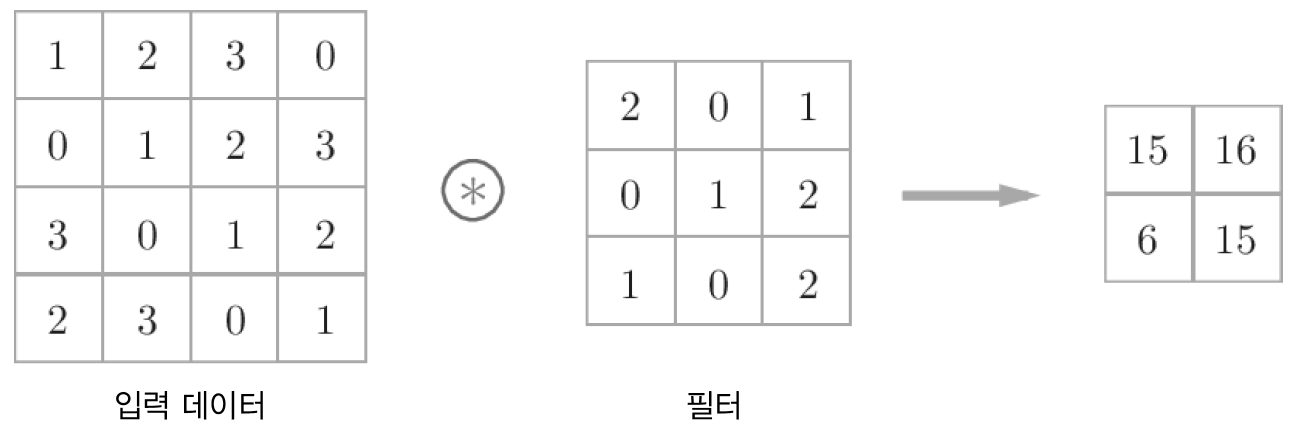

FC(완전연결 신경망)에는 가중치 매개변수와 편향이 존재했는데, CNN에서는 필터의 매개변수가 '가중치'가 된다. CNN에서 편향을 추가하면 다음과 같은 과정이 된다.

2. 3차원 데이터의 합성곱 연산
가장 대표적인 3차원 데이터인 이미지는 (채널,세로,가로)로 이루어져있는 데이터이다. 이렇게 채널까지 고려해야하는 3차원 데이터의 합성곱 연산은 다음과 같이 이뤄진다.


2차원일 때와 비교하면 길이 방향(채널방향)으로 특징 맵이 들어났음을 알 수 있다. 채널 쪽으로 특징 맵이 여러 개 있다면 입력 데이터(입력 특징 맵)와 필터의 합성곱 연산을 채널마다 수행하고 그 결과를 더해서 하나의 출력값을 얻는다.
여기서 주의할 점은 입력 데이터(입력 특징 맵)의 채널 수와 필터의 채널 수가 같아야 한다는 것이다.
합성곱 연산을 블록으로 생각하기
3차원의 합성곱 연산을 블록으로 생각하면 더 쉽다. 데이터를 (채널(C), 높이(H), 너비(W))의 형상을 지닌 입력 데이터와 (채널(C), 필터 높이(FH), 필터 너비(FW))의 형상을 지닌 필터의 합성곱 연산을 블록을 나타내면 다음과 같다.
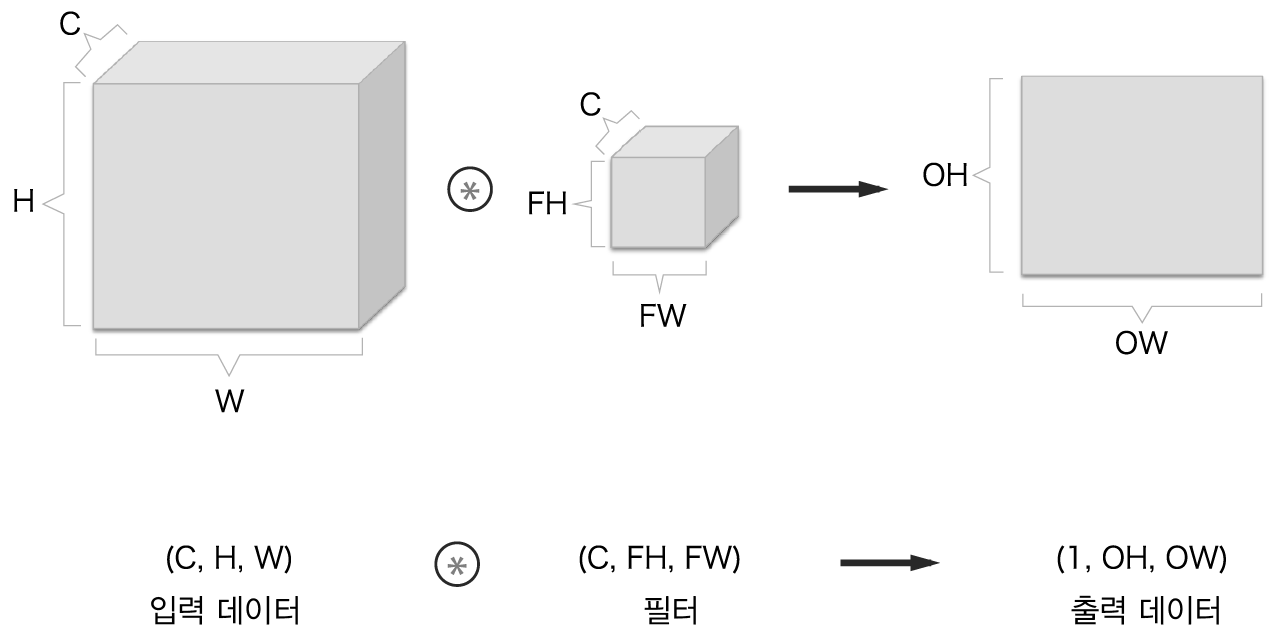
이 예시에서 출력 데이터(출려 특징 맵)은 한 장이다. 그러나 일반적으로 합성곱 연산에서는 다수의 채널을 출력 맵으로 내보낸다. 이를 위해 필터(가중치)를 다수 사용한다.

FN개의 필터를 적용하였더니 FN개의 출력 맵이 생성되었음을 알 수 있다. CNN의 처리 흐름은 (C,H,W) 형상의 입력 특징 맵에 (FN,C,FH,FW) 형상의 필터를 적용하여 (FN,OH,OW) 형상의 출력 특징 맵을 만들고, 이를 다음 계층으로 넘기는 것이다.
따라서 합성곱 연산에서는 필터의 수도 고려해야할 사항 중 하나임을 알 수 있다. 필터의 가중치 데이터는 4차원 데이터이며, (출력 채널수, 입력 채널 수, 높이, 너비) 순으로 작성한다.

실제 CNN 모델을 구현할 때 입력 데이터를 '배치처리'하는 경우가 많다. 한 배치 묶음에 N개의 데이터가 있는 경우, 합성곱 연산에서 배치처리는 다음과 같이 지원한다.

입력 데이터의 차원을 늘려(데이터 수, 채널 수, 높이, 너비)로 만들었다. 위 이미지를 보면 각 데이터의 선두에 배치용 차원을 추가했음을 알 수 있다. 여기서 주의할 점은 신경망에 4차원 데이터가 하나 흐를 때마다 데이터 N개에 대한 합성곱 연산이 이뤄진다는 것이다. 즉, N회 분의 처리를 한 번에 수행한다는 것!
이제 실제 CNN모델의 합성곱 연산 과정을 들여다 보자!
다음과 같은 cnn 모델이 있다고 가정한다.
배치 사이즈의 크기는 N이라 가정한다.

모델 내부를 살펴보면 2개의 합성곱 계층, 2개의 풀링 계층, 3개의 FC 계층으로 이루어져 있음을 알 수 있다.
또한, 각 레이어마다 입력 채널, 출력 채널 수를 알 수 있으며 합성곱 계층과 풀링 계층의 경우엔 스트라이드와 패딩 값도 알 수 있다.


위 모델의 연산 과정을 다음과 같이 나타낸 적 있다.

모델의 연산 과정을 블록으로 생각하여 아래와 같이 조금 더 자세하게 풀어낼 수 있다.

이미지 출처 및 참고 자료
https://github.com/WegraLee/deep-learning-from-scratch/tree/master/ch03
GitHub - WegraLee/deep-learning-from-scratch: 『밑바닥부터 시작하는 딥러닝』(한빛미디어, 2017)
『밑바닥부터 시작하는 딥러닝』(한빛미디어, 2017). Contribute to WegraLee/deep-learning-from-scratch development by creating an account on GitHub.
github.com
'딥러닝' 카테고리의 다른 글
| [컴퓨터비전] CNN (0) | 2021.07.22 |
|---|---|
| [Deep Learning] AutoEncoder(AE) (0) | 2021.07.17 |
| [Deep Learning] Initialization, Optimizer (0) | 2021.07.16 |
| [Deep Learning] Dropout, Activation Function, Batch Normalization (0) | 2021.07.16 |
| [AI Background] 인공 신경망 & MNIST 실습 (0) | 2021.07.13 |