
티스토리 뷰
AutoEncoder
오토인코더는 비지도학습 인공지능이다. 즉, 입력 데이터를 가공하여 목표값을 출력하는 방식이 아니라, 레이블 정보가 없는 데이터 특성을 분석하거나 추출하는 방식이다. AE는 입력과 출력이 동일하며 좌우를 대칭으로 구축된 구조를 지닌다. 비지도 학습 문제를 지도 학습 문제로 바꾸어서 해결한 방법이라 불리기도 한다.

중간에 위치한 Hidden Layer의 앞부분을 '인코더', 뒷부분을 '디코더'라 한다. 오토인코더는 Input data에 대해 Hidden layer로 인코딩(압축)한 후 다시 원래 Input Data로 디코딩(복원)하는 개념이라 볼 수 있다. AE를 활용하면 Input Data를 Latent Space에 압축시켜 이 값을 새로운 Feature로 사용할 수 있다. 이 새로운 Feature를 사용하면 기존의 Feature를 사용할 때보다 성능이 좋고 차원을 줄일 수 있다는 장점이 있다.
AE가 나온 후 AE의 변형 모델이 나오기 시작했다. 바로 SAE와 DAE이다.
Stacked AutoEncoder
SAE는 AE를 쌓아 올린 모델이다. '좋은 Feature를 지니고 있는 Hidden Layer를 쌓아 네트워크를 학습시키면 더 좋은 모델을 만들 수 있을 것이다'라는 개념을 지니고 있다. 학습 과정은 다음과 같다.
①. input data로 AE1 학습
②. ①에서 학습된 모형의 Hidden Layer를 Input으로 하여 AE2를 학습
③. ②과정 반복
④. ① ~ ③과정에서 학습된 Hidden Layer를 쌓아 올림
⑤. 마지막 Layer에 classification 기능이 있는 Output Layer 추가
⑥. 전체 다층 신경망 재학습(Fine-tuning)
Denoising AutoEncoder
DAE는 좀 더 강건한 Feature을 만들기 위한 AE이다. AE와 마찬가지로 Input 데이터를 잘 복원하도록 학습시키는 모델이지만, Input에 약간의 Noise를 추가하여 학습시킨다. 즉, Input이 x+noise이고, Output이 x인 것이다.
FashionMNIST를 활용한 AutoEncoder 모델 설계
이렇게만 정리해두니 무슨 말인지 제대로 와닿지 않는다. 교재의 실습을 진행하면서 이해에 부족한 부분을 채워나가야겠다.
사용할 데이터 셋은 FashionMNIST 데이터이다. 이는 torchvision 내의 datasets 함수를 이용해서 다운로드 받을 수 있다.
전반적인 과정은 MNIST 손글씨 데이터 셋 실습 때와 같다.
필요한 모듈을 선언하고, 장비를 확인하고, 데이터까지 다운받았다. 배치사이즈는 32, EPOCHS은 1로 설정했다(교재에서는 10으로 설정했는데 CPU로 실습하다보니 학습속도가 느려서..그냥 1로 설정했다).
FashionMNIST 데이터셋에 대해서 추가적으로 설명하자면,
train_dataset에는 총 60000개, test_dataset에는 10000개의 이미지데이터가 존재한다.
이 두 데이터를 가지고 배치사이즈(32) 별로 분할해 둔 것이 train_loader, test_loader이다.
train_loader에는 총 1875개의 배치가 존재하며, 각 배치에는 32개의 이미지 데이터가 존재한다.
test_loader에는 총 313개의 배치가 존재하며, 각 배치에는 32개의 이미지 데이터가 존재한다.
데이터를 확인해보면,
X_train 1개는 (32,1,28,28)크기로 28*28크기의 흑백 이미지(1)가 32개 들어가 있음을 알 수 있다.
y_train 1개는 X_train 1개의 라벨 값이기 때문에, 32개의 이미지에 대한 라벨 값으로 총 32개의 데이터가 들어가 있다.

다음으로는 AE를 정의해준다. 인코더와 디코더 부분을 나눠서 설계하였다. 이 AE 모델에 배치별로 데이터를 넣어서 학습하면 (32, 28*28) 크기의 이미지 데이터가 생성된다. AE 모델을 거쳐 생성된 이미지 데이터를 decoded라는 변수에 저장해 둔다.
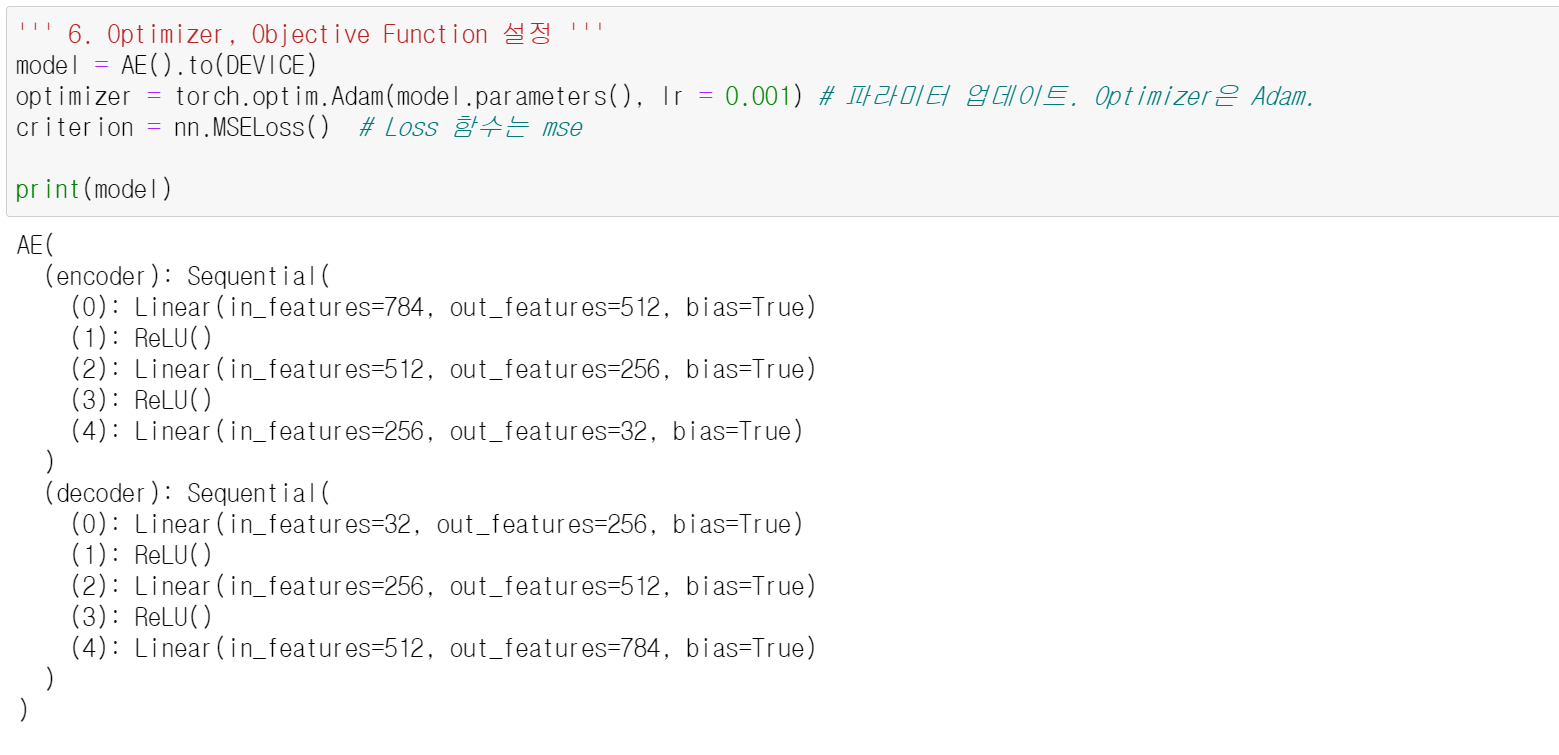
최적화와 매개변수 갱신에 필요한 도구(optimizer, criterion)를 정의하였다. 이에 대한 설명은 생략하겠다.

이제 모델 학습을 진행하는 과정을 구현하는데, 여기서 주의할 점은 train_loader의 데이터들이 2차원 이미지 데이터라는 것이다. AE 모델을 학습시키기 위해서 이 INPUT으로 들어갈 1개의 이미지 데이터들이 1차원이 되어야 한다. 따라서 image 변수에 view(-1,28*28)를 적용하여 1차원 데이터로 만들어준다.
✅ 참고로 image 변수는 루프를 돌면서 train_loader에 들어있는 미니배치 하나씩 가져와 학습을 진행한다. 그리고 view가 적용된 image변수에는 다음과 같은 형태(32, 28*28)로 데이터가 들어있다.

이제 검증 데이터에 대해서 학습을 진행하는 부분이다. 검증데이터도 마찬가지로 trest_loader에 들어있는 배치별로 view(-1, 28*28)를 적용하여 1차원 데이터로 변환 후(image 변수) AE 모델에 넣어준다.
이때 실제 이미지 데이터를 저장하는 real_image()와 AE를 통해 생성되는 gen_image()라는 리스트를 만들어서 이미지 데이터를 저장해둔다.
✅ 여기서 알고 넘어가야 하는 것이 있다!
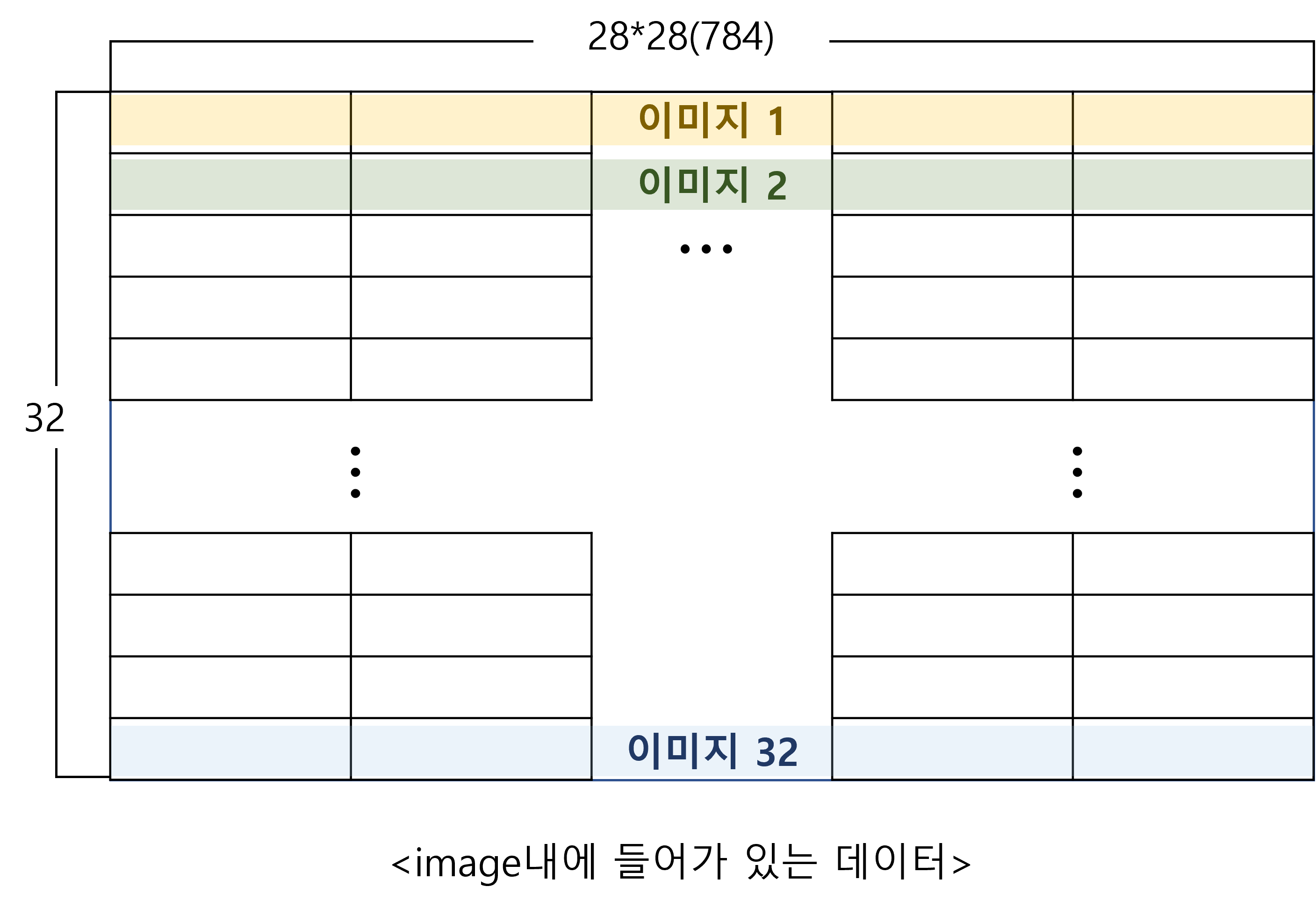
real_image에는 <그림1>에 해당하는 데이터 셋트가 미니배치 갯수만큼 들어가 있다. 즉, test_loader에 들어있는 미니배치 갯수가 313개 이므로 <그림1> 형태의 데이터가 313개 들어있다고 보면 된다. -> (32,28*28)인 데이터 313개
gen_image에도 마찬가지로 <그림1>형태의 데이터 셋트가 313개 들어가 있다. -> (32,28*28)인 데이터 313개

이제 본격적으로 AE 모델 학습을 실행해준다.
아까 에폭을 1로 설정해뒀기 때문에 전체 데이터 셋트는 1번 학습한다. 생성된 이미지를 저장해둔 gen_image, 원본 이미지를 저장해둔 real_image 리스트 모두 1차원 데이터 값이 저장되어 있는데, 이미지를 확인하기 위해선 이 값을 다시 2차원으로 만들어야한다.
이를 # 진행 과정 모니터링에서 수행하게 되는데, reshape() 을 적용하여 형태를 변경해준다.
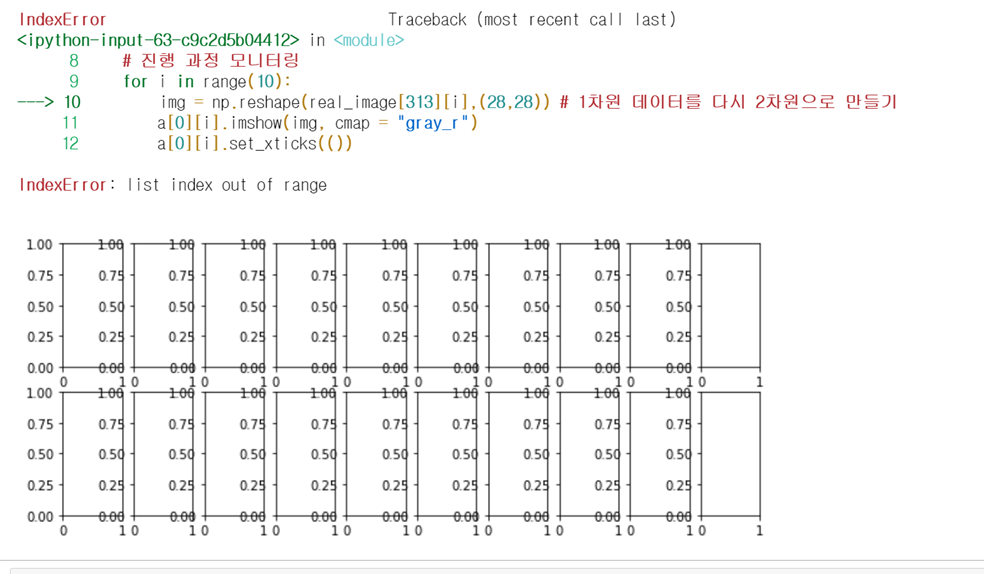
이때 real_image[배치 인덱스][이미지 인덱스](gen_image도 동일) 임을 유의하자! 나는 가장 마지막 배치인 312번째 배치를 불러왔다. 그리고 총 10개의 이미지를 불러오기 위해서 range(10)으로 설정하고 크기는 (28,28)로 설정했다. 만약 [배치 인덱스]에 최댓값인 312를 넘어선 값을 부여하게 되면 아래와 같은 오류가 뜬다!
아무튼, AE모델에 test_loader 데이터 셋을 입력하여 생성해 낸 gen_image와 real_image에 존재하는 313개의 배치데이터 중 가장 마지막 배치(312번)에 존재하는 데이터 10개를 2차원 이미지 데이터로 변형한 후, 불러오면 다음과 같은 결과가 출력된다.
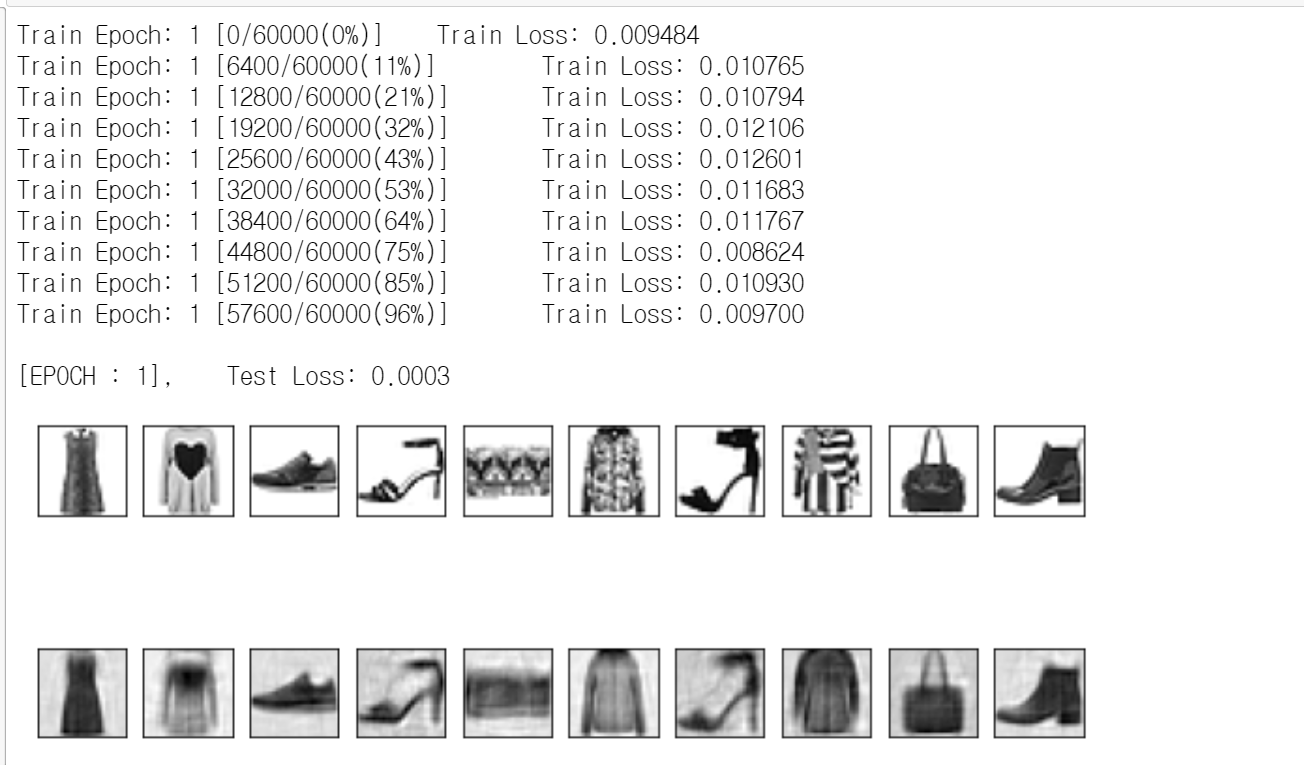
학습이 정상적으로 이뤄지고 있음을 알 수 있다.
'딥러닝' 카테고리의 다른 글
| feature / 가중치 / 노드 수 / MLP&CNN 모델 구조 (0) | 2021.08.20 |
|---|---|
| [컴퓨터비전] CNN (0) | 2021.07.22 |
| [Deep Learning] Initialization, Optimizer (0) | 2021.07.16 |
| [Deep Learning] Dropout, Activation Function, Batch Normalization (0) | 2021.07.16 |
| [AI Background] 인공 신경망 & MNIST 실습 (0) | 2021.07.13 |